Explora
La metodología del análisis textual digital presupone que los textos adquieren significado no de forma aislada, sino como un sistema, un gran corpus. En los grandes corpus textuales digitales pueden aparecen una y otra vez elementos que la lectura humana pasaría por alto al concentrarse únicamente en el detalle y lo lineal. El macroanálisis, la lectura maquínica o lectura distante, en palabras de Mathew Jockers, Stephen Ramsay o Franco Moretti, hace intervenir al elemento computacional y algorítmico y pone en juego métodos cuantitativos que no descartan los métodos cualitativos, pero donde la cantidad siempre precede a la calidad: primero las computadoras procesan datos y luego (idealmente) los humanos los leemos y entendemos en tanto texto. Ofrecemos, a continuación, algunas experiencias de análisis textual en textos de nuestra Biblioteca Digital: La Relación de las cosas sucedidas en el Río de la Plata de Pero Hernández, la Relación de un viaje al Río de la Plata de Acarete du Biscay y La Argentina Manuscrita de Ruy Díaz de Guzmán.
Etiquetado morfosintáctico
El etiquetado morfosintáctico es un procedimiento de anotación automática que asigna una categoría gramatical (o parte del discurso, part-of-speech) a cada token de un texto. Esta técnica de permite visualizar dependencias sintácticas o investigar la correlación entre una determinada clase de palabras y otras características discursivas como polaridad de sentimientos o calidad de escritura.

Análisis de coocurrencias
Las categorías gramaticales pueden utilizarse para el análisis de coocurrencias y así lograr una aproximación rápida del contenido de un corpus textual. El análisis de coocurrencias mide la aparición de dos o más tokens dentro de un mismo contexto (oración, párrafo, etc.). El cálculo de coocurrencias de sustantivos en la Relación de un viaje al Río de la Plata, ilustrado en el siguiente grafo, por ejemplo, permite comprender fácilmente la relevancia de la dimensión comercial y de la descripción del territorio en el texto de Acarete du Biscay a través de la alta frecuencia de los pares “barco-mercadería”, “mina-plata”, “corona-libra”, en un caso, y “legua-río”, “ciudad-río”, “montaña-plata”, en el otro.

Etiquetado semántico
La anotación semántica normalmente busca distinguir las categorías de persona, lugar y evento. Pero también puede servirse de una taxonomía para identificar clases más específicas como jerarquías profesionales, divisiones administrativas o tipos de accidentes geográficos.

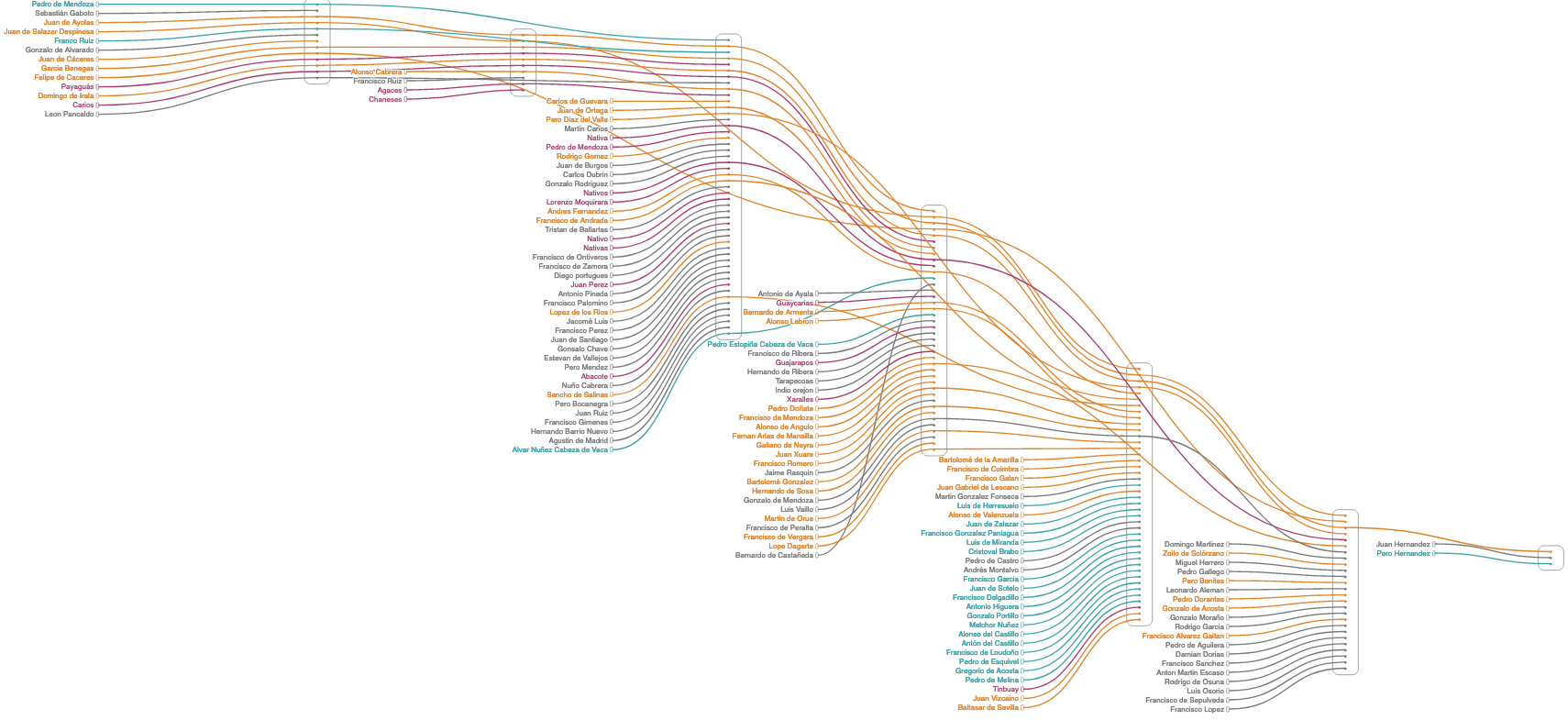
Este enriquecimiento semántico permite, por ejemplo, contabilizar la cantidad de personajes según origen, facción o cargo o trazar los cruces entre estas categorías a lo largo de la trama textual, como en el siguiente diagrama de narrativa de Relación de las cosas sucedidas en el Río de la Plata:
Topic modeling
El topic modeling es un método de organización de grandes corpus basado en aprendizaje automático. Esta técnica permite detectar los tópicos presentes en una colección textual, los documentos que responden a cada tópico y las palabras que lo representan sin necesidad de datos etiquetados.

El siguiente gráfico muestra las diez palabras más representativas de cada tópico para una experiencia de modelización de tópicos para Relación de las cosas sucedidas, Relación de un viaje al Río de la Plata y La Argentina Manuscrita. El tópico 2 presenta palabras muy representativas de la Relación de las cosas sucedidas (el texto da cuenta del enfrentamiento entre Domingo de Irala y el Gobernador, Álvar Núñez) y el tópico 1 muestra palabras como “capitán” y “pedro”, muy caractrísticas de La Argentina Manuscrita (el texto relata la fundación de Asunción realizada por uno de los capitanes de Pedro de Mendoza). Es importante señalar que encontramos palabras repetidas entre tópicos (“río”, “indios”, “plata”), lo cual es lógico si tenemos en cuenta que los textos seleccionados tocan temas en común ya que todos tratan sobre la colonización de zona del Río de la Plata a fines del siglo XVI - principios del siglo XVII.
